JCHLA / JABSC 37: 121–123 (2016) doi: 10.5596/c16-022
Mendeley Data
Purpose: General-purpose research data repository.
URL: https://data.mendeley.com/.
Cost: Free.
Bottom line: Elsevier’s Mendeley Data product is attractive, easy to use, and functional. Nevertheless, its relatively late entry onto the research data repository landscape means that it lags behind competitors in terms of number of datasets published, search functionality, sharing features, and citation features. Further integration with Elsevier’s lab bench notebook HiveBench, as well as forthcoming integration with Elsevier’s research profiling tool Pure, may increase the appeal of Mendeley Data for researchers seeking a seamless, unified workflow.
Online research data repositories provide services that allow researchers to manage, publish, share, and access research data. Data repositories are becoming increasingly important as funding agencies adopt policies and make statements that promote the stewardship and reuse of digital data. For example, the Canadian federal granting agencies (CIHR, NSERC, SSHRC) published a Statement of Principles on Digital Data Management in June 2016 [1].
There are a number of different types of research data repositories, including discipline-specific data repositories (e.g., GenBANK, UniProt), institutional data repositories (e.g., University of Alberta Libraries Dataverse Network), and general-purpose data repositories (e.g., Dryad). Each type of repository has benefits and drawbacks in relation to both sharing data and long-term data preservation [2]. Research data repositories can be operated by noncommercial organizations (e.g., Zenodo, a project of CERN and OpenAIRE) or be owned by commercial companies (e.g., FigShare, a product owned by Macmillan Publishers).
Mendeley Data, a product of Elsevier, is one of the newest entrants in the research data repository landscape; the platform was released in April 2016 [3]. Mendeley Data is a general-purpose repository, allowing researchers in any field to upload and publish research data. Mendeley Data also allows researchers to share unpublished data privately with research collaborators.
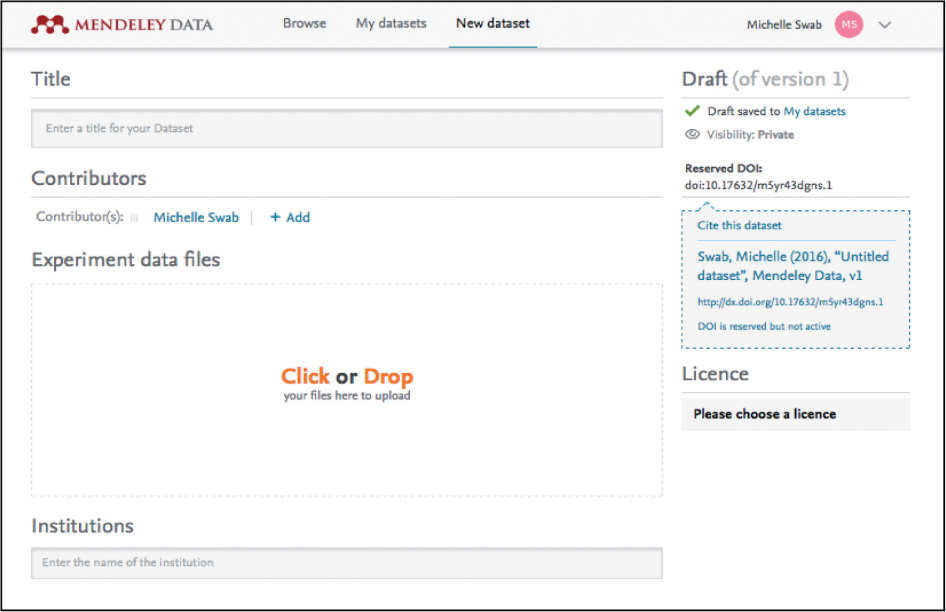
Creating a dataset in Mendeley Data is a simple, user-friendly process. After registering for a Mendeley account, users can create new datasets. Individual data files can be added to the dataset via drag and drop or by selecting files from the user’s computer (Figure 1).
Fig. 1. Mendeley Data file upload page.
Users are prompted to enter a title, add contributors, and assign subject categories for the dataset. Users can also include steps for reproducing the experiment and related links. A DataCite DOI is automatically reserved for each dataset. The DOI becomes active upon publication.
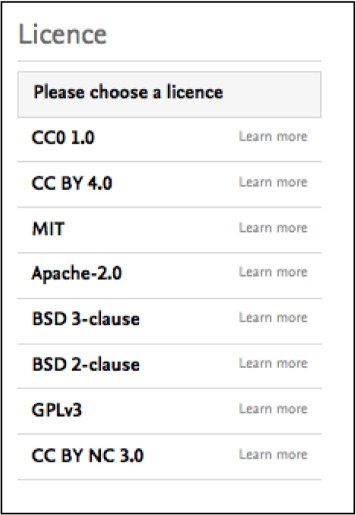
In addition, users are asked to choose a license for data reuse. “Learn More” links provide further information about each license; descriptions are concise but they are easy to understand (Figure 2).
Fig. 2.
A number of data reuse licenses are available.
Any file format can be uploaded. File sizes are limited to 10 GB per dataset. I uploaded several files to test upload speed and file size limits. Mendeley Data performed well when uploading individual files with sizes of up to 2 GB. Tests with larger individual file sizes (4 GB and 7 GB) were less successful, as uploads stalled or displayed messages noting that only 10 GB could be uploaded per dataset. These results may not be typical.
Published datasets can be edited. Edited datasets receive a new version number.
At present, Mendeley Data datasets can only be viewed by using the browse feature. Published datasets are listed in reverse chronological order (Figure 3).
Fig. 3.
Datasets can only be viewed by using the browse feature.
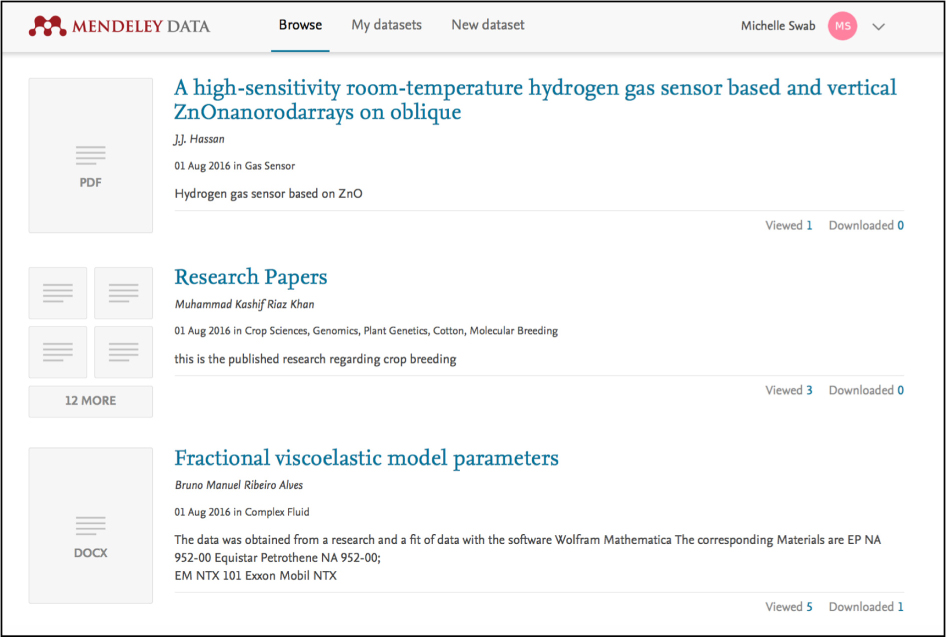
The Mendeley Data FAQ notes that keyword searching and subject browse features are in development [4].
Mendeley Data displays view and download statistics for each dataset.
Datasets are stored on Amazon S3 servers in Germany. Mendeley Data has partnered with Data Archiving and Networked Services (DANS) to provide long-term preservation and archiving of submitted datasets. DANS is an institute of the Royal Netherlands Academy of Arts and Sciences and the Netherlands Organisation for Scientific Research.
When choosing a data repository, researchers should consider a variety of factors including funder requirements, journal publisher requirements, institutional requirements, and disciplinary norms. Type of repository is important, as are the features of specific research data repository services.
As a general-purpose, commercially owned repository, Figshare is an appropriate comparator for Mendeley Data. Figshare was launched in 2011, and thus has a significant lead over Mendeley Data in terms of numbers of datasets published. Assante et al [5] reported that 72,818 datasets were published through Figshare in 2015. Mendeley Data has published less than 250 datasets at the time of writing. Figshare also provides a number of features that are not yet available in Mendeley Data including a variety of search functions, ORCID integration, display of Altmetric badges and citation statistics, and options for bibliographic citation export.
Costs of the two products are comparable. Mendeley Data is currently free, although the Mendeley Data FAQ notes that a Freemium model may be implemented in the future [4]. Figshare accounts provide unlimited public sharing space and up to 20 GB of private space for free [6].
Elsevier acquired laboratory notebook tool HiveBench in July 2016. Future plans include further integration of Mendeley Data with HiveBench as well as the integration of Mendeley Data with Elsevier’s research profiling tool Pure [7]. Integration with HiveBench and Pure may be appealing for researchers interested in a seamless, unified workflow. The acquisition and integration of these products also allows Elsevier to compete with the integrated research workflow currently offered by Macmillan. The 101 Innovations in Scholarly Communications website provides sample workflows in the Elsevier and Springer/Macmillan/NPG/Digital Science environments [8, 9].
Michelle Swab
Public Services Librarian
Health Sciences Library
Memorial University of Newfoundland
St. John’s, NL
Email: mswab@mun.ca
| 1. | science.gc.ca. Tri-Agency Statement of Principles on Digital Data Management [Internet]. [cited 1 Aug 2016]. Available from: http://www.science.gc.ca/default.asp?lang=En&n=83F7624E-1 |
| 2. | Whyte A. Where to keep research data: DCC checklist for evaluating data repositories [Internet]. Edinburgh: Digital Curation Centre; 2015 [cited 1 Aug 2016]. Available from: http://www.dcc.ac.uk/resources/how-guides-checklists/where-keep-research-data |
| 3. | Josh. Mendeley Data is out of beta [Internet]. London: Mendeley Blog; 2016 [cited 1 Aug 2016]. Available from: https://blog.mendeley.com/2016/04/28/mendeley-data-is-out-of-beta/ |
| 4. | Mendeley Data. Mendeley Data FAQ [Internet]. London: Mendeley Data; c2016 [cited 1 Aug 2016]. Available from: https://data.mendeley.com/faq |
| 5. | Assante M, Candela L, Castelli D, Tani A. Are scientific data repositories coping with research data publishing? Data Sci J. 2016;15. doi:10.5334/dsj-2016-006 |
| 6. | Figshare. Figshare features [Internet]. London: Figshare; c2016 [cited 1 Aug 2016]. Available from: https://figshare.com/features |
| 7. | PTavner. Putting data in the hands of researchers with Hivebench [Internet]. London: Mendeley Blog; 2016 [cited 1 Aug 2016]. Available from: https://blog.mendeley.com/2016/06/07/putting-data-in-the-hands-of-researchers-with-hivebench/ |
| 8. | Bosman J, Kramer B. Elsevier workflow [Internet]. Utrecht, The Netherlands: 101 Innovations in scholarly communication; c2016 [cited 1 Aug 2016]. Available from: https://innoscholcomm.silk.co/page/Elsevier |
| 9. | Bosman J, Kramer B. Springer/Macmillan/NPG/Digital Science workflow [Internet]. Utrecht, The Netherlands: 101 Innovations in scholarly communication; c2016 [cited 1 Aug 2016]. Available from: https://innoscholcomm.silk.co/page/Springer-Macmillan-NPG-Digital-Science |